
I am currently a third-year Ph.D. student at the Institute of Artificial Intelligence at Peking University, where I'm part of both the CoRe Lab and the General Vision Lab, under the guidance of Tengyu Liu, Siyuan Huang, and Yixin Zhu. Additionally, I'm undertaking an internship at NVIDIA.
My research focuses on human motion generation, robotics, scene understanding, and leveraging AI for scientific discovery, particularly in the field of biology. Moving forward, my research will focus on how embodied agents can execute actions based on open-vocabulary instructions within real-world environments. I graduated from Beihang University, advised by Guizhen Yu and Yunpeng Wang.
🔥 News
- 2026.03: Presented a talk at the GRASP Lab, University of Pennsylvania
- 2026.03: Presentated latest work at GTC 2026, NVIDIA
- 2025.10: 🎉 One paper is accepted by NeurIPS 2025 Workshop EMBODIED-WORLD-MODELS
- 2025.08: 🎉 One paper is accepted by CoRL 2025
- 2025.06: Presented at the AIR-SUN lab, Institute for AI Industry Research (AIR), Tsinghua University
- 2025.02: 🎉 One paper is accepted by CVPR 2025 as an oral presentation
- 2024.06: Presented at CVPR workshop MANGO
- 2024.03: 🎉 One demo is accepted by 3DV 2024 demo track
- 2024.02: 🎉 One paper is accepted by CVPR 2024
📝 Preprints

OmniClone: Engineering a Robust, All-RounderWhole-Body Humanoid Teleoperation System
Yixuan Li*, Le Ma*, Yutang Lin*, Yushi Du, Mengya Liu, Kaizhe Hu, Jieming Cui, Yixin Zhu†, Wei Liang†, Baoxiong Jia†, Siyuan Huang†
We introduce OmniClone, a whole-body humanoid teleoperation system that achieves high-fidelity, multi-skill control spanning dexterous manipulation and coordinated locomotion. The full pipeline runs on a single consumer GPU and is trained with modest demonstration data, making responsive whole-body teleoperation practical without prohibitive compute or collection cost.
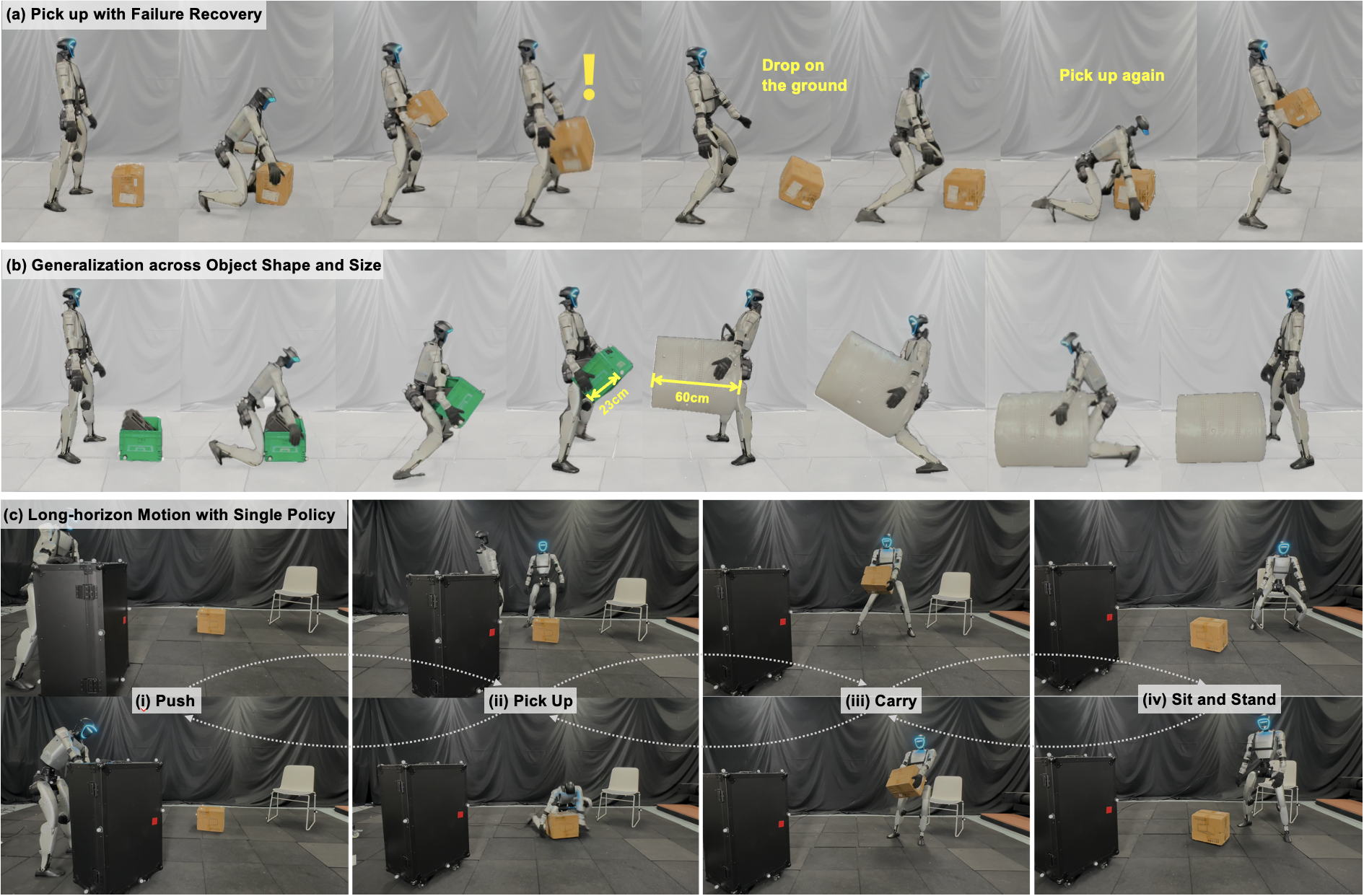
LessMimic: Long-Horizon Humanoid Interaction with Unified Distance Field Representations
Yutang Lin*, Jieming Cui*, Yixuan Li, Baoxiong Jia, Yixin Zhu†, Siyuan Huang†
Project / Code / Video / Paper
We introduce LessMimic, a unified interaction representation enabling reference-free inference, geometric generalization, and long-horizon skill composition within one policy remains an open challenge.
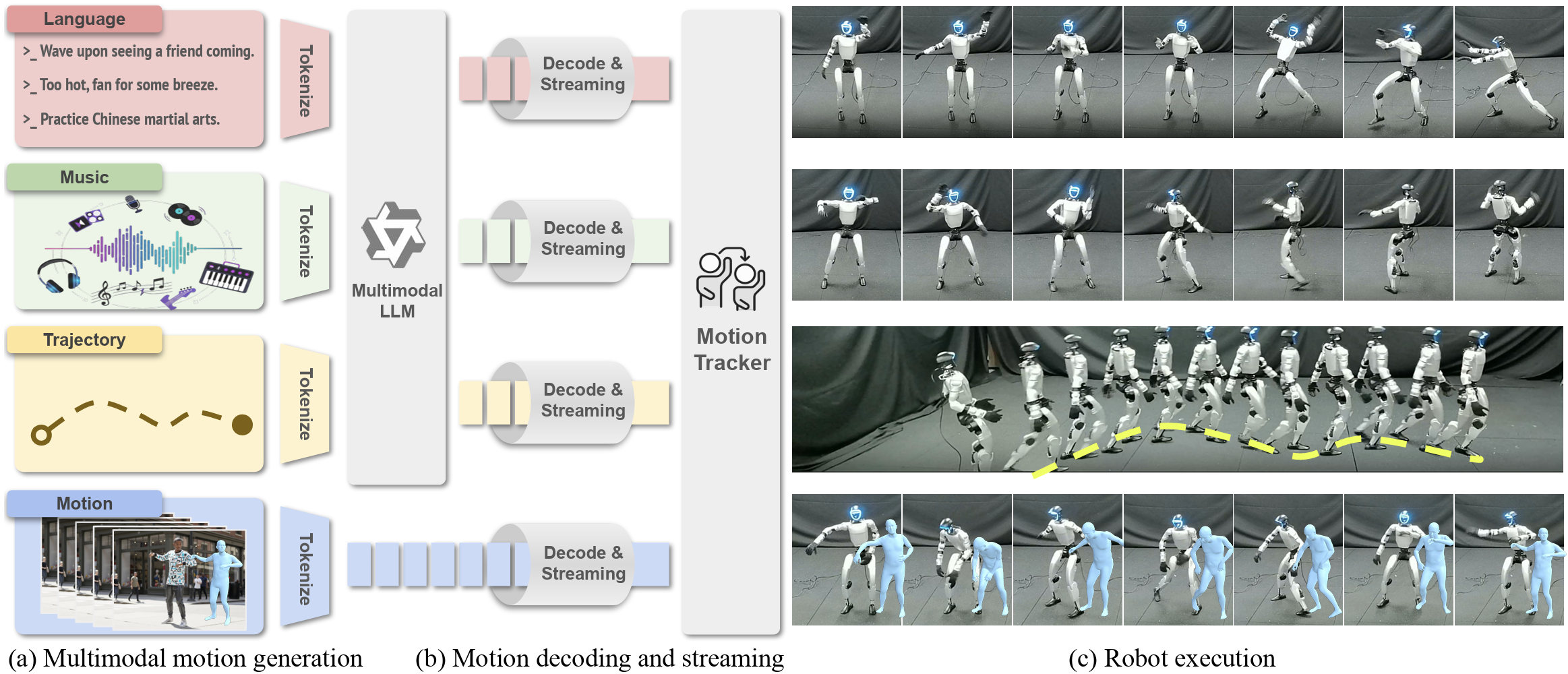
UniAct: Unified Motion Generation and Action Streaming for Humanoid Robots
Nan Jiang*, Zimo He*, Wanhe Yu, Lexi Pang, Yunhao Li, Hongjie Li, Jieming Cui, Yuhan Li, Zizhou Wang, Yixin Zhu†, Siyuan Huang†
Project / Code / Video / Paper
We introduce UniAct, a two-stage framework integrating a fine-tuned MLLM with a causal streaming pipeline, enabling humanoid robots to execute multimodal instructions with sub-500ms latency.
📝 Publications

CLONE: Closed-Loop Whole-Body Humanoid Teleoperation for Long-Horizon Tasks
Yixuan Li*, Yutang Lin*, Jieming Cui, Tengyu Liu, Wei Liang, Yixin Zhu†, Siyuan Huang†
Project / Code / Video / Paper
We introduce CLONE, an MoE-based policy with closed-loop error correction for holistic humanoid teleoperation. It enables capabilities previously unattainable with existing systems—such as whole-body coordination and long-horizon task execution, with minimal input from a commercial MR headset.

GROVE: A Generalized Reward for Learning Open-Vocabulary Physical Skill
Jieming Cui*, Tengyu Liu*, Ziyu Meng, Jiale Yu,Ran Song,Wei Zhang, Yixin Zhu†, Siyuan Huang†
Project / Code / Video / Paper / 北大新闻网 / 北大科研进展速览
We introduce GROVE, a generalized reward framework that enables open-vocabulary physical skill learning without manual engineering or task-specific demonstrations.

AnySkill: Learning Open-Vocabulary Physical Skill for Interactive Agents
Jieming Cui*, Tengyu Liu*, Nian Liu*, Yaodong Yang, Yixin Zhu†, Siyuan Huang†
Project / Code / Video / Paper
We propose AnySkill, a novel hierarchical method that learns physically plausible interactions following open-vocabulary instructions. An important feature of our method is the use of image-based rewards for the high-level policy, which allows the agent to learn interactions with objects without manual reward engineering.
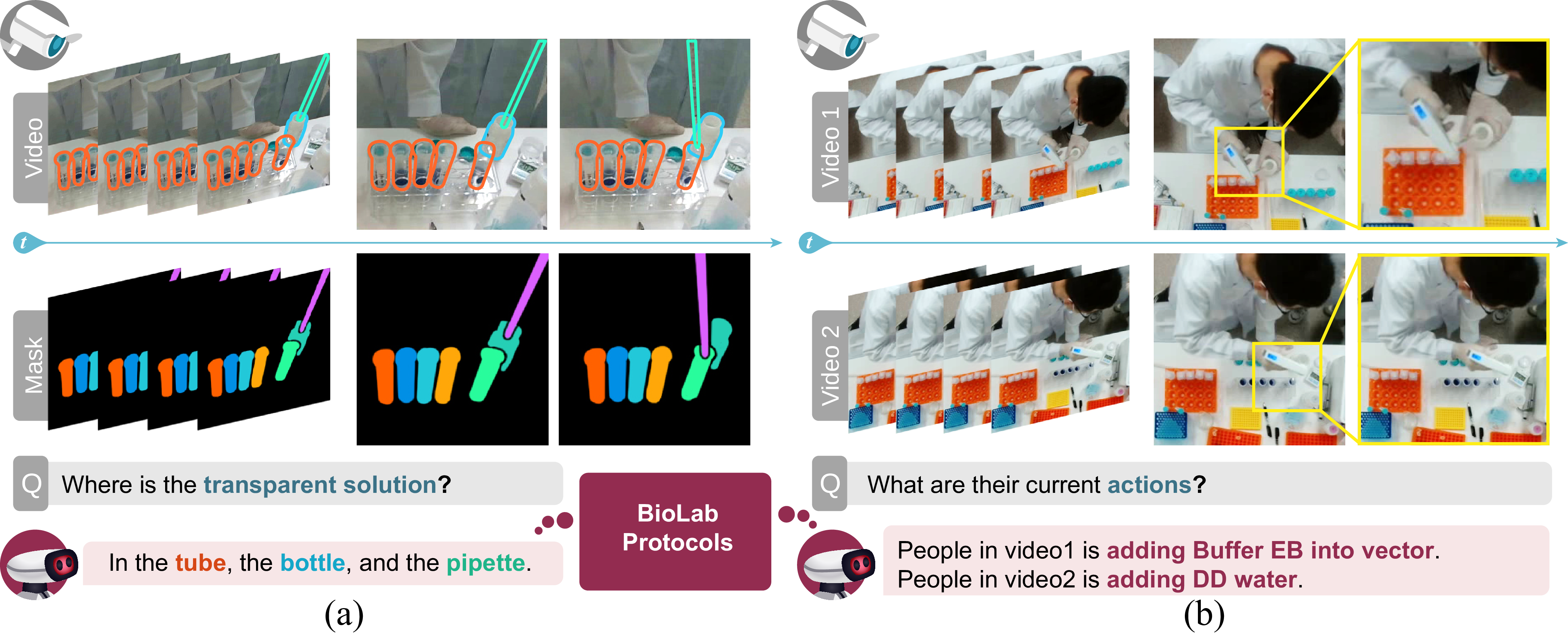
ProBio: A Protocol-guided Multimodal Dataset for Molecular Biology Lab
Jieming Cui*, Ziren Gong* , Baoxiong Jia*, Siyuan Huang, Zilong Zheng†, Jianzhu Ma†, Yixin Zhu†
Project / Code / Video / Paper / 北大AI院官微
We first curate a comprehensive multimodal dataset, named ProBio, as an initial step towards monitoring system. This dataset comprises fine-grained hierarchical annotations intended for the purpose of studying activity understanding in Biology lab.

Full-Body Articulated Human-Object Interaction
Nan Jiang*, Tengyu Liu*, Zhexuan Cao, Jieming Cui, He Wang, Yixin Zhu†, Siyuan Huang†
We present CHAIRS, a large-scale motion-captured f-AHOI dataset, consisting of 16.2 hours of versatile interactions between 46 participants and 74 articulated and rigid sittable objects. CHAIRS provides 3D meshes of both humans and articulated objects during the entire interactive process, as well as realistic and physically plausible full-body interactions.
ASCE 2021
Forecasting Freeway On-Ramp Lane-Changing Behavior Based on GRU,
Jieming Cui*, Guizhen Yu* , Bin Zhou, Qiujun Liu, Zhengguo Guan†
SAE 2021
Three-Dimensional Object Detection Based on Deep Learning in Enclosed Scenario,
Jieming Cui*, Guizhen Yu* , Na Zhang, Zhangyu Wang
📖 Educations
- 2023.09 - now, PhD, Peking University, Beijing.
- 2019.09 - 2022.02, Master, Beihang University, Beijing.
- 2015.09 - 2019.06, Undergraduate, Beijing Jiaotong University, Beijing.
💻 Internships
- 2022.02 - now, BIGAI, Beijing.
- 2021.06 - 2021.09, Amap, Alibaba, Beijing.
- 2020.02 - 2021.06, Tage Zhixing, Beijing.